

总站

- 课程
- 学校
- 老师
总站
课程原价:
面议
优 惠 价:
面议
更新日期:
2024/11/22
开课形式:
准时开班
上课时段:
白天班
课程人气:
已有 16796 人浏览
授课学校:
上课地址:
上海黄浦区津路180号/北京东路668号
咨询电话:
400-168-8684

上海海文国际教育-其它课程
课程类别
课程名称
开班时间
学费
课程内容详细介绍
高度契合企业需求的良心课程

Linux系统做为大数据平的企业级操作系统,本部分是基础课程,帮大家打好Linux基础,以便更好地学习Hadoop,hbase,NoSQL,Spark,Storm,docker,openstack等众多课程。这是进入大数据领域的必须掌握的基础技术因为企业中的项目基本上都是使用Linux环境下搭建或部署的。
本课程是整套大数据课程的基石:其一,分布式文件系统HDFS用于存储海量数据,无论是Hive、HBase或者Spark分析的数据是存储在HDFS里面;其二是分布式资源管理框架YARN是用来在Hadoop 云操作系统(也称数据系统)管理集群资源和分布式数据处理框架MapReduce、Spark应用的资源调度与监控的;分布式并行计算框架MapReduce目前是海量数据并行处理的一个最常用的框架。Hadoop 2.x的编译、环境搭建、HDFS Shell使用,YARN 集群资源管理与任务监控,MapReduce编程,分布式集群的部署管理(包括高可用性HA)必须要掌握的。
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供基本的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库mysql、Oracle、SQLServer、postgresql等RDBMS数据间进行数据的传递,可以将一个关系型数据库,例如 : MySQL 、Oracle 、SQLServer、Postgres等RDBMS中的数据导进到关系型数据库中。Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python Web框架Django实现的。通过使用Hue我们可以在浏览器端的Web控制台上与Hadoop集群进行交互来分析处理数据,例如操作HDFS上的数据,运行MapReduce Job等等。
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。HBase在Hadoop之上提供了类似于Bigtable的能力,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群;
Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop。 随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍,比如网站统计、推荐系统、预警系统、金融系统(高频交易、股票)等等, 大数据实时处理解决方案(流计算)的应用日趋广泛,目前已是分布式技术领域最新爆发点,而Storm更是流式计算技术中的佼佼者和主流。 按照storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。Hadoop提供了map + reduce的原语,使我们的批处理程序变得简单和高效。 同样,Storm也为实时计算提供了一些简单高效的原语,而且Storm的Trident是基于Storm原语更高级的抽象框架,类似于基于Hadoop的Pig框架, 让开发更加便利和高效。本课程会深入、全面的讲解Storm,并穿插企业场景实战讲述Storm的运用。 淘宝双11的大屏幕实时监控效果冲击了整个IT界,业界为之惊叹的同时更是引起对该技术的探索。 学完本课程你可以自己开发升级版的“淘宝双11”,一起来学习吧!
为什么要学习Scala?源于Spark的流行,Spark是当前最流行的开源大数据内存计算框架,采用Scala语言实现,各大公司都在使用Spark:IBM宣布承诺大力推进Apache Spark项目,并称该项目为:在以数据为主导的,未来十年最为重要的新的开源项目。这一承诺的核心是将Spark嵌入IBM业内领先的分析和商务平台,Scala具有数据处理的天然优势,Scala是未来大数据处理的主流语言;
Spark是UC Berkeley AMP lab所开源的类,是Hadoop MapReduce的通用并行框架,Spark拥有Hadoop MapReduce所具有的优点。启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark Streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似batch批量处理的方式来处理这小部分数据;
本课程主要讲解目前大数据领域热门、火爆、有前景的技术――Spark。在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战。课程会涵盖Scala编程详解、Spark核心编程.
本阶段主要就之前所学内容完成大数据相关企业场景与解决方案的剖析应用及结合一个电子商务平台进行实战分析,主要包括有: 企业大数据平台概述、搭建企业大数据平台、真实服务器手把手环境部署、使用CM 5.3.x管理CDH 5.3.x集群;
离线数据分析平台是一种利用hadoop集群开发工具的一种方式,主要作用是帮助公司对网站的应用有一个比较好的了解。尤其是在电商、旅游、银行、证券、游戏等领域有非常广泛,因为这些领域对数据和用户的特性把握要求比较高,所以对于离线数据的分析就有比较高的要求了。 本课程讲师本人之前在游戏、旅游等公司专门从事离线数据分析平台的搭建和开发等,通过此项目将所有大数据内容贯穿,并前后展示!
课程基于1号店的业务及数据进行设计和讲解的,主要涉及:
1、课程中完整开发3个Storm项目,均为企业实际项目,其中一个是完全由Storm Trident开发。 项目源码均可以直接运行,也可直接用于商用或企业。
2、每个技术均采用最新稳定版本,学完后会员可以从Kafka到Storm项目开发及HighCharts图表开发一个人搞定!让学员身价剧增;
3、搭建CDH5生态环境完整平台,且采用Cloudera Manager界面化管理CDH5平台。让Hadoop平台环境搭建和维护都变得轻而易举。
4、分享实际项目的架构设计、优劣分析和取舍、经验技巧,陡直提升学员的经验值;
本阶段通过对历来大数据公司企业真实面试题的剖析,讲解,让学员真正的一个菜鸟转型为具有1年以上的大数据开发工作经验的专业人士,也是讲师多年来大数据企业开发的经验之谈。
国内关于Java性能调优的课程非常少,如此全面深入介绍Java性能调优; 本套课程系多年工作经验与心得的总结,课程有着很高的含金量和实用价值,本课程专注于java应用程序的优化方法,技巧和思想,深入剖析软件设计层面、代码层面、JVM虚拟机层面的优化方法,理论结合实际,使用丰富的示例帮助学员理解理论知识。
Java自面世后就非常流行,发展迅速,对C++语言形成有力冲击。在全球云计算和移动互联网的产业环境下,JAVA更具备了显著优势和广阔前景,基于JAVA的项目也越来越多,对JAVA运行环境的要求也越来越高,很多JAVA的程序员只知道对业务的扩展而不知道对java本身的运行环境的调试,例如虚拟机调优,服务器集群等,所以也滋生本门课程的产生。 本课程重点讲解JAVA企业级开发中必须掌握的应用服务器;
随着互联网的发展,高并发、大数据量的网站要求越来越高。而这些高要求都是基础的技术和细节组合而成的。本课程就从实际案例出发给大家原景重现高并发架构常用技术点及详细演练。通过该课程的学习,普通的技术人员就可以快速搭建起千万级的高并发大数据网站平台,课程涉及内容包括:LVS实现负载均衡、Nginx高级配置实战、共享存储实现动态内容静态化加速实战、缓存平台安装配置使用、mysql主从复制安装配置实战等。
随着Web技术的普及,Internet上的各类网站每天都在爆炸式增长。但这些网站大多在性能上没做过多考虑。当然,各种情况不同。有的是Web技术本身的原因(主要是程序代码问题),还有就是由于Web服务器未进行优化。不管是哪种情况,一但用户量在短时间内激增,网站就会明显变慢,甚至拒绝放访问。要想有效地解决这些问题,就只有依靠不同的优化技术。本课程就是主要用于来解决大型网站性能问题,能够承受大数据、高并发。主要涉及 技术有:nginx、tomcat、memcached、redis缓存、负载均衡等高级开发技术;
项目实战:PB级通用电商网站性能优化解决方案
本部分通过一个通用电商订单支付模块,外加淘宝支付接口的实现(可用于实际项目开发),剖析并分析过程中可能遇到的各种性能瓶颈及相关的解决方案与优化技巧。最终目标,让具备PHP基础或JAVA基础的学员迅速掌握Linux下的开发知识,并对涉及到nginx、tomcat、memcached、redis缓存、负载均衡等高级开发技术有一个全面的了解;
本课程名为深入浅出数据挖掘技术。所谓“深入”,指得是从数据挖掘的原理与经典算法入手。其一是要了解算法,知道什么场景应当应用什么样的方法;其二是学习算法的经典思想,可以将它应用到其他的实际项目之中;其三是理解算法,让数据挖掘的算法能够应用到您的项目开发之中去。所谓“浅出”,指得是将数据挖掘算法的应用落实到实际的应用中。课程会通过三个不同的方面来讲解算法的应用:一是微软公司的SQL Server与Excel等工具实现的数据挖掘;二是著名开源算法的数据挖掘,如Weka、KNIMA、Tanagra等开源工具;三是利用C#语言做演示来完成数据挖掘算法的实现。根据实际的引用场景,数据挖掘技术通常分为分类器、关联分析、聚类算法等三大类别。本课程主要介绍这三大算法的经典思想以及部分著名的实现形式,并结合一些商业分析工具、开源工具或编程等方式来讲解具体的应用方法;
本课程由浅入深的介绍了Lucene4的发展历史,开发环境搭建,分析lucene4的中文分词原理,深入讲了lucenne4的系统架构,分析lucene4索引实现原理及性能优化,了解关于lucene4的搜索算法优化及利用java结合lucene4实现类百度文库的全文检索功能等相对高端实用的内容,市面上一般很难找到同类具有相同深度与广度的视频,集原理、基础、案例与实战与一身,不可多得的一部高端视频教程;
本教程从最基础的solr语法开始讲解,选择了最新最流行的开源搜索引擎服务框架solr5.3.1,利用Tomcat8搭建了solr的集群服务;本教程可以帮助学员快速上手solr的开发和二次开发,包括在hadoop集群的使用,海量数据的索引和实时检索,通过了解、学习、安装、配置、集成等步骤引导学员如何将solr集成到项目中;
SPSS Modeler是业界极为著名的数据挖掘软件,其前身为SPSS Clementine。SPSS Modeler内置丰富的数据挖掘模型,以其强大的挖掘功能和友好的操作习惯,深受用户的喜爱和好评,成为众多知名企业在数据挖掘项目上的软件产品选择。本课程以SPSS Modeler为应用软件,以数据挖掘项目生命周期为线索,以实际数据挖掘项目为例,讲解了从项目商业理解开始,到最后软件实现的全过程。
ETL是数据的抽取、清洗、转换、加载的过程,是数据进入数据仓库进行大数据分析的载入过程,目前流行的数据进入仓库的过程有两种形式,一种是进入数据库后再进行清洗和转换,另外一条路线是首先进行清洗转换再进入数据库,我们的ETL属于后者。 大数据的利器大家可能普遍说是hadoop,但是大家要知道如果我们不做预先的清洗和转换处理,我们进入hadoop后仅通过mapreduce进行数据清洗转换再进行分析,垃圾数据会导致我们的磁盘占用量会相当大,这样无形中提升了我们的硬件成本(硬盘大,内存小处理速度会很慢,内存大但CPU性能低速度也会受影响),因此虽然hadoop理论上解决了一堆普通服务器拼起来解决大问题的问题,但是事实上如果我们有更好的节点速度必然是会普遍提升的,因此ETL在大数据环境下仍然是必不可少的数据交换工具;
本课程面向从未接触过数据分析的学员,从最基础的R语法开始讲起,逐步进入到目前各行业流行的各种分析模型。整个课程分为基础和实战两个单元:基础部分包括R语法和统计思维两个主题、R语法单元会介绍R语言中的各种特色数据结构,以及如何从外部抓取数据,如何使用包和函数,帮助学员快速通过语法关。统计思维单元会指导如何用统计学的思想快速的发现数据特点或者模式,并利用R强大的绘图能力做可视化展现。在实战部分选择了回归、聚类、数据降维、关联规则、决策树这5中最基础的数据分析模型,详细介绍其思想原理,并通过案例讲解R中的实现方案,尤其是详细的介绍了对各种参数和输出结果的解读,让学员真正达到融会贯通、举一反三的效果。并应用到自己的工作环境中;
Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。课程包括:Mahout数据挖掘工具,及Hadoop实现推荐系统的综合实战,涉及到MapReduce、Pig和Mahout的综合实战;
近年来,金融领域的量化分析越来越受到理论界与实务界的重视,量化分析的技术也取得了较大的进展,成为备受关注的一个热点领域。所谓金融量化,就是将金融分析理论与计算机编程技术相结合,更为有效的利用现代计算技术实现准确的金融资产定价以及交易机会的发现。量化分析目前已经涉及到金融领域的方方面面,包括基础和衍生品金融资产定价、风险管理、量化投资等。随着大数据技术的发展,量化分析还逐步与大数据结合在一起,对海量金融数据实现有效和快速的运算与处理。在量化金融的时代,选用一种合适的编程语言对于金融模型的实现是至关重要的。在这方面,Python语言体现出了不一般的优势,特别是它拥有大量的金融计算库,并且可以提供与C++,java等语言的接口以实现高效率的分析,成为金融领域快速开发和应用的一种关键语言,由于它是开源的,降低了金融计算的成本,而且还通过广泛的社交网络提供大量的应用实例,极大的缩短了金融量化分析的学习路径。本课程在量化分析与Python语言快速发展的背景下介绍二者之间的关联,使学员能够快速掌握如何利用Python语言进行金融数据量化分析的基本方法。
本课程介绍了基于云计算的大数据处理技术,重点介绍了一款高效的、实时分析处理海量数据的强有力工具――数据立方。数据立方是针对大数据处理的分布式数据库,能够可靠地对大数据进行实时处理,具有即时响应多用户并发请求的能力,通过对当前主流的大数据处理系统进行深入剖析,阐述了数据立方产生的背景,介绍了数据立方的整体架构以及安装和详细开发流程,并给出了4个完整的数据立方综合应用实例。所有实例都经过验证并附有详细的步骤说明,无论是对于云计算的初学者还是想进一步深入学习大数据处理技术的研发人员、研究人员都有很好的参考价值。
ZooKeeper是Hadoop的开源子项目(Google Chubby的开源实现),它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、命名服务、分布式同步、组服务等。Zookeeper的Fast Fail 和 Leader选举特性大大增强了分布式集群的稳定和健壮性,并且解决了Master/Slave模式的单点故障重大隐患,这是越来越多的分布式产品如HBase、Storm(流计算)、S4(流计算)等强依赖Zookeeper的原因。Zookeeper在分布式集群(Hadoop生态圈)中的地位越来越突出,对分布式应用的开发也提供了极大便利,这是迫切需要深入学习Zookeeper的原因。
本课程主要内容包括Zookeeper深入、客户端开发(Java编程,案例开发)、日常运维、Web界面监控,“一条龙”的实战平台分享给大家;
Docker是一种开源的应用容器引擎,使用Docker可以快速地实现虚拟化,并且实现虚拟化的性能相对于其他技术来说较高。并且随着云计算的普及以及对虚拟化技术的大量需求,使得云计算人才供不应求,所以一些大型企业对Docker专业技术人才需求较大。本教程从最基础的Dokcer原理开始讲起,深入浅出,并且全套课程均结合实例实战进行讲解,让学员可以不仅能了解原理,更能够实际地去使用这门技术;
2013年,云计算领域从此多了一个名词“Docker”。以轻量著称,更好的去解决应用打包和部署。之前我们一直在构建Iaas,但通过Iaas去实现统一功 能还是相当复杂得,并且维护复杂。将特殊性封装到镜像中实现几乎一致得部署方法,它就是“Docker”,以容器为技术核心,实现了应用的标准化。企业可以快速生成研发、测试环境,并且可以做到快速部署。实现了从产品研发环境到部署环境的一致化。Docker让研发更加专注于代码的编写,并且以“镜像”作 为交付。极大的缩短了产品的交付周期和实施周期;
OpenStack是一个由Rackspace发起、全球开发者共同参与的开源项目,旨在打造易于部署、功能丰富且易于扩展的云计算平台。OpenStack企图成为数据中心的操作系统,即云操作系统。从项目发起之初,OpenStack就几乎赢得了所有IT巨头的关注,在各种OpenStack技术会议上人们激情澎湃,几乎所有人都成为OpenStack的信徒。 这个课程重点放在Openstack的部署和网络部分。课程强调实际的动手操作,使用vmware模拟实际的物理平台,让大家可以自己动手去实际搭建和学习Openstack。课程内容包括云计算的基本知识、虚拟网络基础、Openstack部署和应用、Openstack网络详解等;
本课程希望用简单易懂的语言带领大家探索TensorFlow(基于1.0版本API)。课程中讲师主讲TensorFlow的基础原理,TF和其他框架的异同。并用具体的代码完整地实现了各种类型的深度神经网络:AutoEncoder、MLP、CNN(AlexNet,VGGNet,Inception Net,ResNet)、Word2Vec、RNN(LSTM,Bi-RNN)、Deep Reinforcement Learning(Policy Network、Value Network)。此外,还讲解了TensorBoard、多GPU并行、分布式并行、TF.Learn和其他TF.Contrib组件。本课程能帮读者快速入门TensorFlow和深度学习,在工业界或者研究中快速地将想法落地为可实践的模型;
本课程重点讲解开发推荐系统的方法,尤其是许多经典算法,重点探讨如何衡量推荐系统的有效性。课程内容分为基本概念和进展两部分:前者涉及协同推荐、基于内容的推荐、基于知识的推荐、混合推荐方法,推荐系统的解释、评估推荐系统和实例分析;后者包括针对推荐系统的攻击、在线消费决策、推荐系统和下一代互联网以及普通环境中的推荐。课程中包含大量的图、表和示例,有助于学员理解和把握相关知识等:
本课程主要讲解人工智能的基本原理、实现技术及其应用,国内外人工智能研究领域的进展和发展方向。内容主要分为4个部分:
第1部分是搜索与问题求解,系统地叙述了人工智能中各种搜索方法求解的原理和方法,内容包括状态空间和传统的图搜索算法、和声算法、禁忌搜索算法、遗传算法、免疫算法、粒子群算法、蚁群算法和Agent技术等;
第2部分为知识与推理,讨论各种知识表示和处理技术、各种典型的推理技术,还包括非经典逻辑推理技术和非协调逻辑推理技术;
第3部分为学习与发现,讨论传统的机器学习算法、神经网络学习算法、数据挖掘和知识发现技术;
第4部分为领域应用,分别讨论专家系统开发技术和自然语言处理原理和方法。 通过对这些内容的讲解能够使学员对人工智能的基本概念和人工智能系统的构造方法有一个比较清楚的认识,对人工智能研究领域里的成果有所了解;
本项目采用Java语言实现,绝对基于真实的爬虫项目进行改进和优化,希望进一步提升大家的大数据项目经验。本项目基本涵盖了爬虫项目的整个流程,包括数据爬虫、全文检索、数据可视化、爬虫项目监控、爬虫项目维护等等。解决了爬虫项目中遇到的棘手问题,包括破解网站反爬策略、网站模板定期变更、网站频繁访问IP被封等等问题; 技术架构:
Java、HttpClient、Redis、Solr、HBase、Zookeeper、HighChart、HTMLEmail
本项目主要采用目前大数据领域最成熟的实时计算框架Spark,它是目前主流企业在实时计算方向采用的主流框架。本项目使用了Spark技术生态栈中的三个技术框架:Spark Core、Spark Streaming和Spark MLlib,进行道路交通实时流量监控预测系统的开发。业务实现包括数据产生模块、数据实时收集处理模块、特征数据提取模块、模型预测模块、数据存储模块; 技术架构:
Spark Core、Spark Streaming和Spark MLlib
学校简介

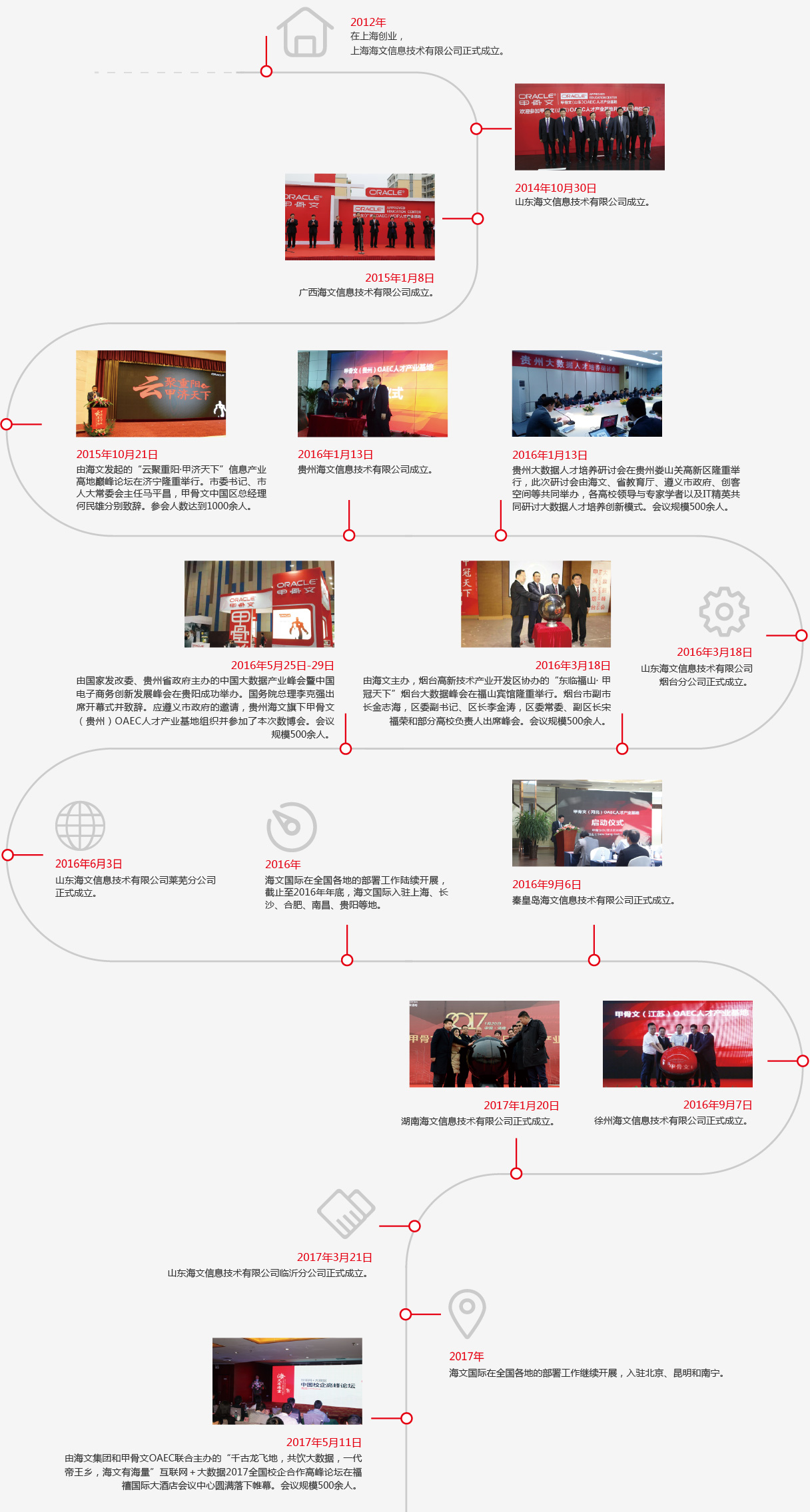
海文创立于2012年,是一家专注于青年人才服务领域的综合型企业机构,是中国领先的科技型人力资源服务提供商。海文通过全面引入甲骨文的技术标准,现已分别在山东济宁、广西北海、贵州遵义、河北秦皇岛、江苏徐州和湖南常德建立六个与甲骨文合作的OAEC人才产业基地,分别在莱芜、烟台建立了两个甲骨文OAEC教育解决方案中心,并在北京、上海、长沙、合肥、南昌、贵阳、昆明等地建立了海文互联网和IT实训中心。
海文通过服务理念和服务模式创新,服务链、价值链、产业链构建,行业人才服务全程支持平台---海文人才、海文国际、海文在线等公共服务平台打造,全面引入甲骨文的技术标准,目前已发展成为一家以18-28岁年龄段青年、用人企业、人才研究机构、政府及社团企业为主要客户对象,以自主开发的互联网和IT实训中心及运营平台为依托,集教育、就业、资讯、服务、技术、解决方案等功能于一体,以线上线下相结合的方式为客户提供人才教育及人才输出解决方案和增值服务的技术型、平台型、资源型、集团型企业。
海文国际是专注于互联网和IT人才培养与输送的现代化职业教育品牌,在中国打造领先的互联网和IT实训中心。目前在上海、长沙、烟台、合肥、南昌、贵阳等地运营面积超过20000平米,同时容纳数千人培训。
海文国际以”求真,务实”的严谨作风,始终致力于为中国培养实战型,紧缺型和创新型的信息化人才。
发展历程
从出生到蜕变,从懵懂到成熟,从一叶扁舟发展为远航巨舸。

上海海文国际教育

